GO Map内部实现
Table of Contents
1 go map操作
map类型不管在哪个语言中都是很常用的类型,它具有O(1)的存取速度。十分高效,虽然内存可能会多占用一点。但是也是非常值得的事情,网上的文章大多是讨论slice的内部结构,很少讨论map,不过map跟slice同作为 引用类型 看看内部实现也是很有必要的。map的操作主要有以下内容:
//创建map a := make(map[string]string) //存入 a["first"] = "first" //读取 fmt.Println(a["first"])
不是所有的key都能作为map的key类型,只有能够比较的类型才能作为key类型。所以例如切片,函数,map类型是不能作为map的key类型的。具体可见https://blog.golang.org/go-maps-in-action。 在go语言中,map是非线程安全的,也就是说go中的map类型不能放在多个goroutine中,只能自己维护线程安全。
2 内部实现
在实现map的过程中,最需要注意的就是 装载因子 ,当它过大时需要增长map的空间,重新映射值到新的空间。
源码位置: $GOROOT/src/runtime/hashmap.go
type hmap struct { // Note: the format of the Hmap is encoded in ../../cmd/internal/gc/reflect.go and // ../reflect/type.go. Don't change this structure without also changing that code! count int // # live cells == size of map. Must be first (used by len() builtin) map中key的个数,被len()函数使用。 flags uint8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) hash0 uint32 // hash seed buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated) // If both key and value do not contain pointers and are inline, then we mark bucket // type as containing no pointers. This avoids scanning such maps. // However, bmap.overflow is a pointer. In order to keep overflow buckets // alive, we store pointers to all overflow buckets in hmap.overflow. // Overflow is used only if key and value do not contain pointers. // overflow[0] contains overflow buckets for hmap.buckets. // overflow[1] contains overflow buckets for hmap.oldbuckets. // The first indirection allows us to reduce static size of hmap. // The second indirection allows to store a pointer to the slice in hiter. overflow *[2]*[]*bmap }
这是源码中map的header,其中buckets主要存放数据,结构如下图所示:

首先buckets指向一个数组的bucket,取值的时候。先对key进行hash算法得到的值假若为h,用h对len(buckets)取余为hl那么就在buckets[hl]这一个链表中找。
对于一个bucket,最多存放8个kv对,以此存放key的hash值的高八位,八个key,八个value,指向下一个bucket的指针。如下图所示:
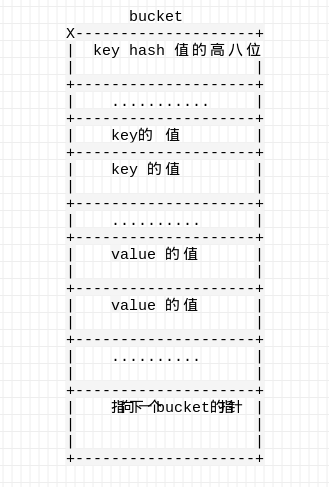 这里key跟key放在一起而不是形成k|v|k|v的原因是减少内存对齐的内存消耗。
这里key跟key放在一起而不是形成k|v|k|v的原因是减少内存对齐的内存消耗。
当map中的kv对越来越多的时候,会造成buckets的重新分配,新的buckets的大小是原来大小的2倍。但是老的buckets的值并不会立即移动到新buckets中来,而是等下一次存或者删除哪个bucket,就移动那一个bucket链。
访问map的源码:
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead // it will return a reference to the zero object for the value type if // the key is not in the map. // NOTE: The returned pointer may keep the whole map live, so don't // hold onto it for very long. func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if raceenabled && h != nil { callerpc := getcallerpc(unsafe.Pointer(&t)) pc := funcPC(mapaccess1) racereadpc(unsafe.Pointer(h), callerpc, pc) raceReadObjectPC(t.key, key, callerpc, pc) } if msanenabled && h != nil { msanread(key, t.key.size) } if h == nil || h.count == 0 { return unsafe.Pointer(&zeroVal[0]) } if h.flags&hashWriting != 0 { throw("concurrent map read and map write") } //得到key的hash函数 alg := t.key.alg hash := alg.hash(key, uintptr(h.hash0)) m := uintptr(1)<<h.B - 1 //根据hash值对m取余找到对于的bucket b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) if c := h.oldbuckets; c != nil { //如果老的bucket还没有迁移,在老的bucket里面找, oldb := (*bmap)(add(c, (hash&(m>>1))*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } } //hash的高8位 top := uint8(hash >> (sys.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } for { for i := uintptr(0); i < bucketCnt; i++ { //如果hash的高8位跟记录的不一样,就找下一个 if b.tophash[i] != top { continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey { k = *((*unsafe.Pointer)(k)) } if alg.equal(key, k) { //如果找到了同一个key,取出value. v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) if t.indirectvalue { v = *((*unsafe.Pointer)(v)) } return v } } //这个bucket没找到,找这个bucket链的下一个bucket b = b.overflow(t) if b == nil { return unsafe.Pointer(&zeroVal[0]) } } }
从map的读取代码中,我们可以看到map的buckets的结构跟前面说的一样.
map存值的源码:
func mapassign1(t *maptype, h *hmap, key unsafe.Pointer, val unsafe.Pointer) { if h == nil { panic(plainError("assignment to entry in nil map")) } if raceenabled { callerpc := getcallerpc(unsafe.Pointer(&t)) pc := funcPC(mapassign1) racewritepc(unsafe.Pointer(h), callerpc, pc) raceReadObjectPC(t.key, key, callerpc, pc) raceReadObjectPC(t.elem, val, callerpc, pc) } if msanenabled { msanread(key, t.key.size) msanread(val, t.elem.size) } if h.flags&hashWriting != 0 { throw("concurrent map writes") } h.flags |= hashWriting //得到key的hash函数 alg := t.key.alg hash := alg.hash(key, uintptr(h.hash0)) //如果buckets为空,则分配一个 if h.buckets == nil { h.buckets = newarray(t.bucket, 1) } again: //得到hash的低b位,等同于对buckets的大小取余 bucket := hash & (uintptr(1)<<h.B - 1) //如果老的bucket还没有迁移,则对老的bucket迁移 if h.oldbuckets != nil { growWork(t, h, bucket) } //根据hash值的低b位找到对于的bucket b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize))) //计算hash值的高8位 top := uint8(hash >> (sys.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } var inserti *uint8 var insertk unsafe.Pointer var insertv unsafe.Pointer for { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == empty && inserti == nil { //如果以后没有找到,这里先预留一个可以插入的位置 inserti = &b.tophash[i] insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) insertv = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) k2 := k if t.indirectkey { k2 = *((*unsafe.Pointer)(k2)) } if !alg.equal(key, k2) { continue } // 找到一个相同的key // already have a mapping for key. Update it. if t.needkeyupdate { typedmemmove(t.key, k2, key) } v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize)) v2 := v if t.indirectvalue { v2 = *((*unsafe.Pointer)(v2)) } //更新值 typedmemmove(t.elem, v2, val) //跳出循环到完成 goto done } ovf := b.overflow(t) if ovf == nil { break } b = ovf } // did not find mapping for key. Allocate new cell & add entry. if float32(h.count) >= loadFactor*float32((uintptr(1)<<h.B)) && h.count >= bucketCnt { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again } //没有找到可以插入的位置,分配一个 if inserti == nil { // all current buckets are full, allocate a new one. newb := (*bmap)(newobject(t.bucket)) h.setoverflow(t, b, newb) inserti = &newb.tophash[0] insertk = add(unsafe.Pointer(newb), dataOffset) insertv = add(insertk, bucketCnt*uintptr(t.keysize)) } // store new key/value at insert position if t.indirectkey { kmem := newobject(t.key) *(*unsafe.Pointer)(insertk) = kmem insertk = kmem } if t.indirectvalue { vmem := newobject(t.elem) *(*unsafe.Pointer)(insertv) = vmem insertv = vmem } //存kv typedmemmove(t.key, insertk, key) typedmemmove(t.elem, insertv, val) *inserti = top h.count++ done: if h.flags&hashWriting == 0 { throw("concurrent map writes") } h.flags &^= hashWriting }
其他的源码就不一一列举了, 有兴趣可以看runtime/hashmap.go。
3 总结
总的来说golang的map类型实现比较中规中矩,亮点是延迟移动bucket。一个bucket能存放8个kv对的设计也很有趣。感觉上综合了链表与数组的优点。